Gladders2000NewMethodGalaxy
可能是 red sequence 方法的起源
red-sequence 不是 photo-z 的一种吗?
Comment #
- 对于 red sequence 的更详细描述:稳定、被动演化、给定红移下颜色最红
- 用星系密度分布示踪 mass 的分布确实是一件 non-trivial 的事情:假定恒定的质光比?
- 光学数据的 selection effect 可以通过 mock 来获得,但是会存在投影导致的 false positive
- 在同一红移下,不同的 cluster 中的 red sequence 是无法区分的
Abs #
- 观测事实:所有的 rich cluster 都包含一个由 early type galaxy 组成的 red sequence
- 形成于同一时期
- 处于被动演化状态
- 比低红移处的正常星系更红
- 可以用 color cut 消除前景的污染
Intro #
- 红移 0-1 之间的 cluster 探测是重要的
- 常见的探测方法包括光学和 X-ray
- 需要假设 cluster 在观测上的表现,所以一定存在选择效应
- X-ray 方法的偏差可能来自于 gas-poor 或者气体呈现 compact 分布的 cluster
- 光学方法的 bias
- optically dark cluster: 具有足够的 halo mass 但是因为一些原因没有形成星系
- 还有可能是 fossil groups
- 椭圆星系的演化是相对简洁的,选择函数比较好计算
- 可以通过 mock and recover 的方法提取出来
- false positive 相比 bias 来说更难确定一些
- 光学方法的 false positive 主要来源于 projection effect
- 这里提出的方法简称为 CRS
- 观测事实是大部分 member galaxy 都满足线性的颜色-星等关系(red sequence)
- 通过位置、颜色、星等空间的 overdensity 来识别 cluster
- 引入颜色或者说红移的约束几乎消除了投影效应的影响
- 只要滤光片 pair 可以采样 4000A break,就可以从巡天数据中分离出 red sequence,不需要更多的信息
- 将 CRS 方法应用于 RCS project
2 CRS method #
- 一个基本的假定是:星系 overdensity 代表了质量的 overdensity
- 也就是假定了恒等的质光比
- 只有 mass distribution 才对宇宙学有用
- cluster 要做的事情主要是:在二维的图像数据中确定星系的三维分布
- matched filter 对于真实星系具有较高的灵敏度,而把难度转移到了 model 过程中
Red sequence 适合作为 probe 的原因 #
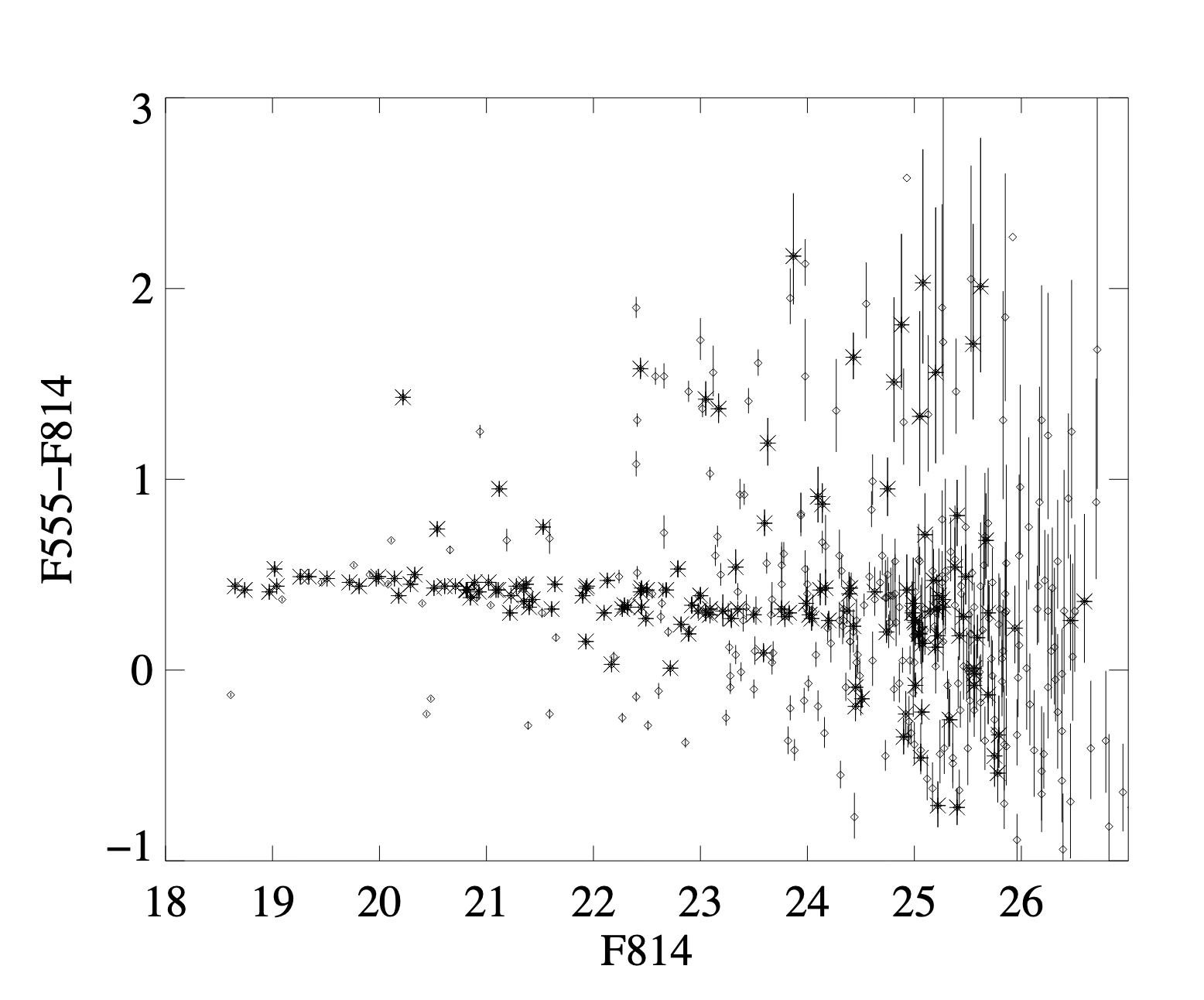
- red sequence 是存在的,并且其性质具有普遍性(across clusters)
- 这些星系似乎形成于很高红移的时期,和 cluster 形成于最早的 over-density 的假设相印证
- 这些星系是年老、稳定的 cluster marker
- cluster 中最亮的星系一般都是椭圆星系
- 高红移的椭圆星系比低红移具有更高的光度
- 主要是因为被动演化星族的亮度衰减
- 由于 morphology-density relation,椭圆星系的排列更加 compact
- 椭圆星系基本是最古老的星系,所以在给定红移下是最红的星系
- 是因为演化比较久没有 SF 吗?
- 其他类型或者更低红移的星系的颜色都更蓝,污染主要来源于更高的红移
- 通过颜色计算出的红移具有很低的 scatter
- 和多波段 photo-z 方法类似,并且优于 matched filter 方法
CRS 所依赖的 red sequence 的假设至少可以持续到 1.3 红移
3 Observational Constraints #
3.1 ETG 的颜色演化 #
- 1992 年发现 Coma 和 Virgo 中的 ETG 是不可区分的
- Coma is rich, massive and luminous 并且以 ETG 为主
- 后来 LCY00 将结论扩展到了更大的样本,至少在 0.2 红移以下是成立的
- 这些 red sequence 星系都具有很高的 formation redshift
- 可能的问题在于:高红移的 cluster 可能在现在具有更高 richness,不能直接对应于低红移相同丰度的 cluster
3.2 ETG 的光度演化 #
主要指的是 ETG fundamental plane 的演化,说明 ETG 的演化本质上是 passive evolution,现在观测到的椭圆星系基本都在 z=2 之前形成
3.3 z>1 的 red sequence 性质 #
由于观测限制目前对于 z>1 的 red sequence 的理解还不足,但是有几个零星的样本,基本都具有 red sequence
高红移的 cluster 普遍是 poor 的,因此 red sequence 的形成早于 cluster assembly,这和 bottom-top hierarchical structure 也一致
4 CRS implementation #
每个星系用四个参数表征:两个参数描述位置,还有星等和颜色(不考虑位置和星等的误差)
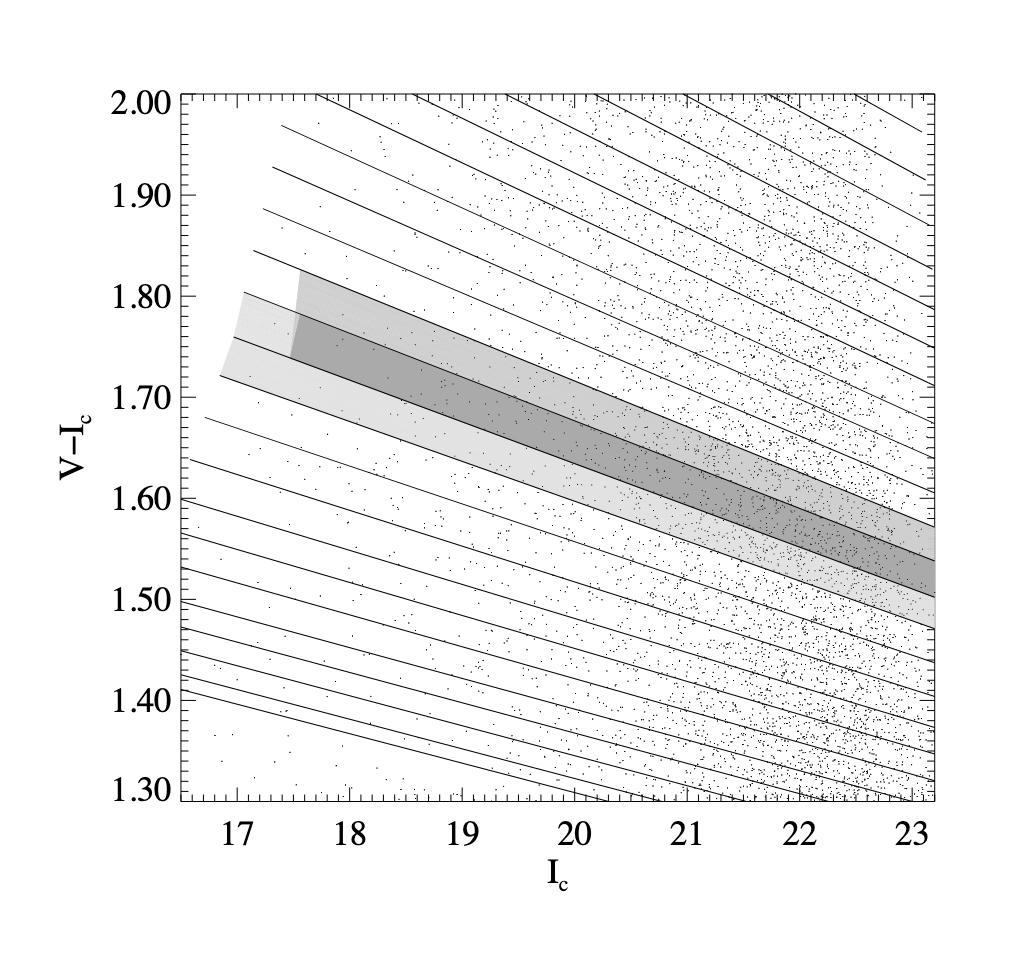
4.1 Color slices #
- 首先要定义一个 red sequence model; 这实际上来源于对 stellar population 的建模
- 模型细节其实不重要,因为会在之后通过 calibration 进行修正
- 根据该模型可以将颜色-星等图划分为不同红移的多个区域,这里的宽度考虑了颜色测量的误差以及 red sequence intrinsic error
- 这里的 slices 需要适当的重叠
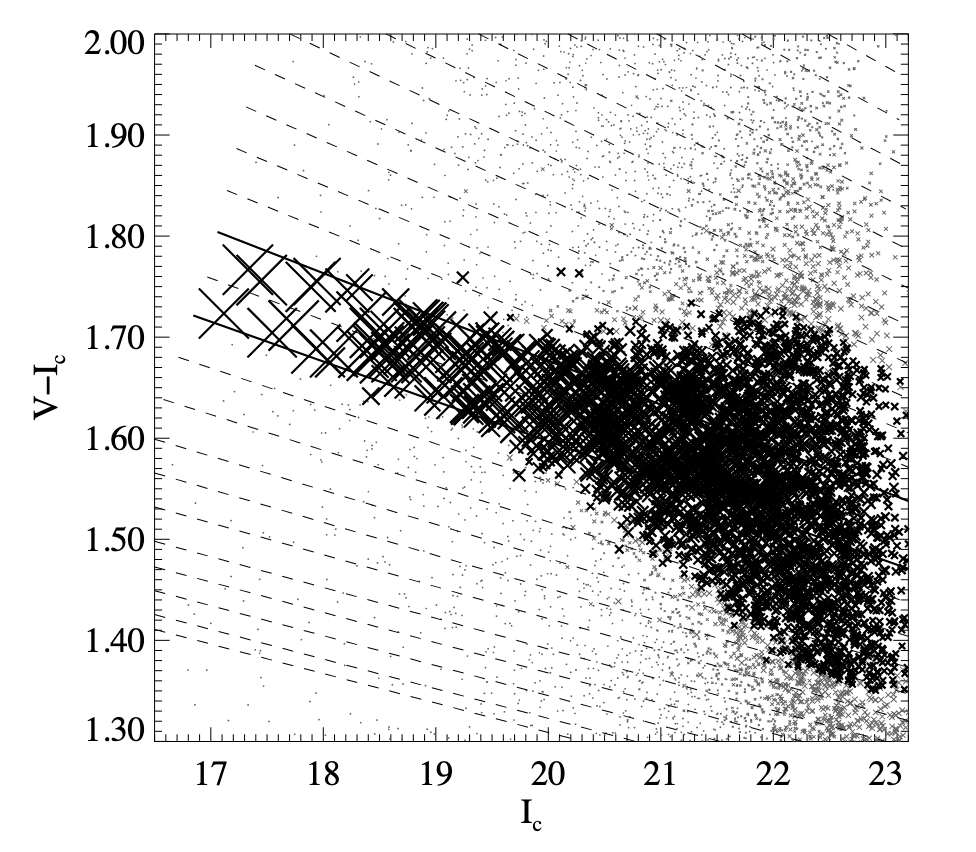
4.2 Galaxy subsets #
对于每一个 slice,以 10% 作为 cutoff 给出属于这个红移区间的 subset
4.3 Galaxy weights #
red sequence 的暗端被 field galaxy 主导(如果没有颜色选择,亮端也会被 field galaxy 主导)
可以根据数据本身对 cluster 和 field 的数目比例进行评估,然后估计
4.4 Density #
采用了 fixed-kernel smoothing 计算星系的 surface density
这里 kernel 的选择并不重要
这里从“merging of the individual 2D density maps into a data cube”开始有点不懂了
用 bootstrap 确定 kernel function 的分布
4.5 Identify clusters #
将每个切片的 probability map 堆叠起来,就得到了 data cube,也就是星系的三维分布
最后要为每一个 cluster 估计一个红移,可以直接从 data cube 中得到
5 Test #
CNOC2 是一个中红移 field galaxy survey,对 40k 星系进行成像和光谱的观测,可以作为 CRS 方法的测试
6 Possible refinements #
- 用最大似然估计替代 slice, smoothing, stacking 步骤
- 加入形态的信息
7 Conclusion #
- red sequence 是 cluster 中普遍存在且性质均匀的特征
- 具体的方法是先根据颜色区分出不同的红移,然后构建二维的平滑密度图,最后合成 data cube,在 cube 中的 over density peak 就是探测到的 cluster
- CRS 的污染率为 5% 左右,红移的精度在 10% 左右
- RCS 的结果在另一篇论文中给出